Démissionnaire depuis le 16 juillet 2024 de sa fonction de ministre de l’Education nationale et de la Jeunesse, tout comme le gouvernement Attal, Nicole Belloubet a tout de même présenté la « rentrée scolaire 2024-2025 ». Le numérique et l’intelligence artificielle sont dans les rangs.
 Dans les « affaires courantes » qu’a gérées la ministre démissionnaire de l’Education nationale et de la Jeunesse, Nicole Belloubet (photo), il y avait la présentation le 27 août des grandes orientations de la « rentrée scolaire 2024-2025 ». Parmi les mesures prises afin que tout puisse se passer au mieux pour les près de 12 millions d’élèves qui, en France, ont repris le chemin de l’école, certaines portent sur les usages du numérique, avec l’instauration cette année de la « pause numérique », ainsi que l’apport de l’intelligence artificielle (IA) pour que les enfants et les enseignants puissent l’utiliser à des fins pédagogiques.
Dans les « affaires courantes » qu’a gérées la ministre démissionnaire de l’Education nationale et de la Jeunesse, Nicole Belloubet (photo), il y avait la présentation le 27 août des grandes orientations de la « rentrée scolaire 2024-2025 ». Parmi les mesures prises afin que tout puisse se passer au mieux pour les près de 12 millions d’élèves qui, en France, ont repris le chemin de l’école, certaines portent sur les usages du numérique, avec l’instauration cette année de la « pause numérique », ainsi que l’apport de l’intelligence artificielle (IA) pour que les enfants et les enseignants puissent l’utiliser à des fins pédagogiques.
De la loi de 2018 à la circulaire de 2024
La mesure-phare est sans doute l’expérimentation de la « pause numérique » dans les collèges. Il s’agit de ni plus ni moins d’interdire les smartphones dans les 6.980 collèges que compte la France. Du moins, cette mesure radicale se fera en deux temps : une première expérimentation a commencé pour cette année scolaire 2024-2025 dans quelque 200 établissements qui se sont portés « volontaires » pour priver plus de 50.000 collégiens de leur téléphone portable. La ministre démissionnaire a précisé que la généralisation de cette mesure devrait intervenir au 1er janvier 2025 et l’avait justifiée dans une circulaire datée du 26 juin 2024 : « Au collège, une “pause numérique” sera expérimentée au sein de collèges volontaires dans chaque département, de telle sorte que l’interdiction de l’usage du portable prévue par la loi [du 3 août 2018, ndlr] soit effective et totale sur l’intégralité du temps scolaire, y compris les espaces interstitiels à risques que sont les changements de classe, les récréations et la pause méridienne ».
Cette circulaire a été publiée au Bulletin officiel de l’éducation nationale, de la jeunesse et des sports (1), lequel est adressé aux recteurs et rectrices d’académie, aux inspecteurs et inspectrices de l’éducation nationale, aux cheffes et chefs d’établissement, aux directeurs et directrices des écoles ; aux professeures et professeurs, ainsi qu’aux personnels administratifs, sociaux et de santé, et aux accompagnantes et accompagnants d’élèves en situation de handicap. Elle fait référence à la loi du 3 août 2018 intitulée « encadrement de l’utilisation du téléphone portable dans les établissements d’enseignement scolaire », laquelle prévoit déjà que « l’utilisation d’un téléphone mobile ou de tout autre équipement terminal de communications électroniques par un élève est interdite dans les écoles maternelles, les écoles élémentaires et les collèges et pendant toute activité liée à l’enseignement qui se déroule à l’extérieur de leur enceinte, à l’exception des circonstances, notamment les usages pédagogiques, et des lieux dans lesquels le règlement intérieur l’autorise expressément » (2).
 Claude d’Anthropic sera-t-elle l’IA générative qui pourra détrôner ChatGPT d’OpenAI ? L’avenir dira si la fable du lièvre et de la tortue s’appliquera à ces deux concurrents Alors que ChatGPT d’OpenAI a été lancé le 30 novembre 2022 avec le succès médiatique planétaire que l’on connaît (
Claude d’Anthropic sera-t-elle l’IA générative qui pourra détrôner ChatGPT d’OpenAI ? L’avenir dira si la fable du lièvre et de la tortue s’appliquera à ces deux concurrents Alors que ChatGPT d’OpenAI a été lancé le 30 novembre 2022 avec le succès médiatique planétaire que l’on connaît (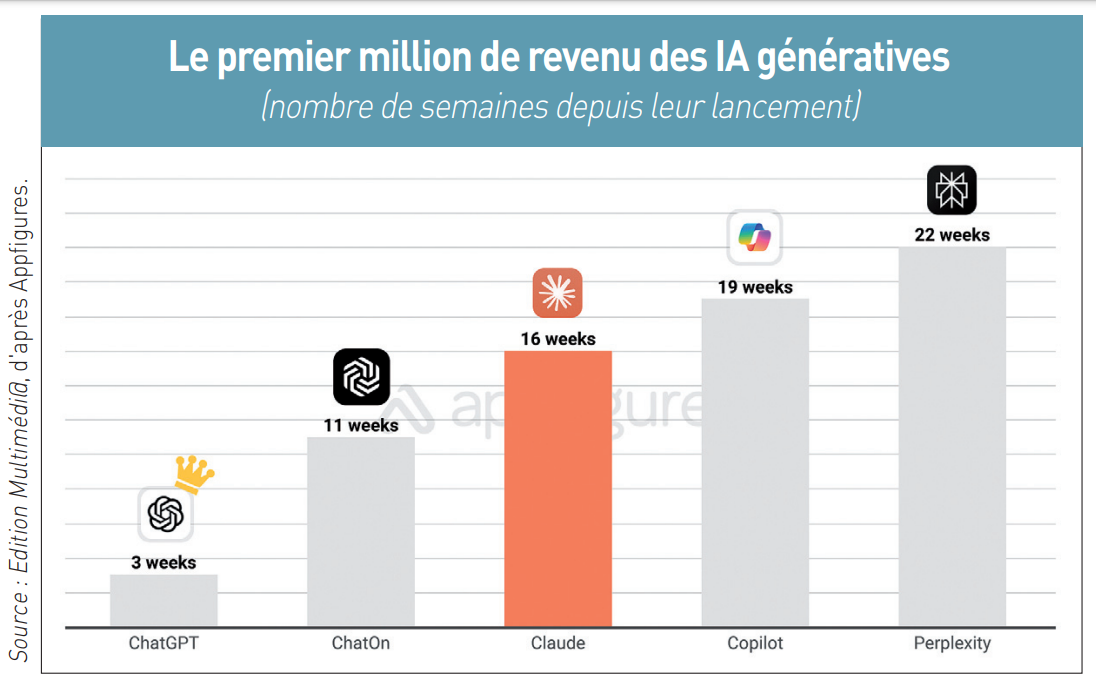 Anthropic a donc plus que jamais une carte à jouer dans la bataille des IA génératives, comme le croit Ariel Michaeli : « Nous estimons que Claude a jusqu’à présent 25.000 abonnés payants. Cela semble beaucoup, mais ChatGPT a ajouté 291.000 nouveaux abonnés payants en juillet [l’IA générative d’OpenAI revendiquant en août plus de 200 millions d’utilisateurs actifs, ndlr]. Pour que Claude ait une chance, il doit apprendre des wrappers et ne pas copier ChatGPT. Si Claude augmente son interface de chat avec des fonctionnalités plus grand public, et s’il promeut son application mobile, alors il pourrait avoir une chance » (
Anthropic a donc plus que jamais une carte à jouer dans la bataille des IA génératives, comme le croit Ariel Michaeli : « Nous estimons que Claude a jusqu’à présent 25.000 abonnés payants. Cela semble beaucoup, mais ChatGPT a ajouté 291.000 nouveaux abonnés payants en juillet [l’IA générative d’OpenAI revendiquant en août plus de 200 millions d’utilisateurs actifs, ndlr]. Pour que Claude ait une chance, il doit apprendre des wrappers et ne pas copier ChatGPT. Si Claude augmente son interface de chat avec des fonctionnalités plus grand public, et s’il promeut son application mobile, alors il pourrait avoir une chance » (