L’émergence fulgurante et extraordinaire de l’intelligence artificielle (IA) soulève aussi des préoccupations légitimes. Sur l’AI Act, un accord entre les Etats membres tarde avant un vote des eurodéputés, alors que 2024 va marquer la fin de la mandature de l’actuelle Commission européenne.
Par Arnaud Touati, avocat associé, Nathan Benzacken, avocat, et Célia Moumine, juriste, Hashtag Avocats.
 Il y a près de trois ans, le 21 avril 2021, la Commission européenne a proposé un règlement visant à établir des règles harmonisées concernant l’intelligence artificielle (IA). Ce règlement européen, appelé AI Act, a fait l’objet, le 9 décembre 2023 lors des trilogues (1), d’un accord provisoire. Mais des Etats européens, dont la France, ont joué les prolongations dans des réunions techniques (2). La dernière version consolidée (3) de ce texte législatif sur l’IA a été remise le 21 janvier aux Etats membres sans savoir s’ils se mettront d’accord entre eux début février, avant un vote incertain au Parlement européen (4).
Il y a près de trois ans, le 21 avril 2021, la Commission européenne a proposé un règlement visant à établir des règles harmonisées concernant l’intelligence artificielle (IA). Ce règlement européen, appelé AI Act, a fait l’objet, le 9 décembre 2023 lors des trilogues (1), d’un accord provisoire. Mais des Etats européens, dont la France, ont joué les prolongations dans des réunions techniques (2). La dernière version consolidée (3) de ce texte législatif sur l’IA a été remise le 21 janvier aux Etats membres sans savoir s’ils se mettront d’accord entre eux début février, avant un vote incertain au Parlement européen (4).
Contours de l’IA : éléments et précisions
Cette proposition de cadre harmonisé a pour objectif de : veiller à ce que les systèmes d’IA mis sur le marché dans l’Union européenne (UE) soient sûrs et respectent la législation en matière de droits fondamentaux et les valeurs de l’UE ; garantir la sécurité juridique pour faciliter les investissements et l’innovation dans le domaine de l’IA ; renforcer la gouvernance et l’application effective de la législation en matière de droits fondamentaux et des exigences de sécurité applicables aux systèmes d’IA; et faciliter le développement d’un marché unique pour les applications d’IA, sûres et dignes de confiance et empêcher la fragmentation du marché (5). Pour résumer, cette règlementation vise à interdire certaines pratiques, définir des exigences pour les systèmes d’IA « à haut risque »et des règles de transparence, tout en visant à minimiser les risques de discrimination et à assurer la conformité avec les droits fondamentaux et la législation existante. Il reste encore au futur AI Act à être formellement adopté par le Parlement et le Conseil européens pour entrer en vigueur.
 L’intelligence artificielle (IA) représente un défi désormais bien connu en matière de droit d’auteur (
L’intelligence artificielle (IA) représente un défi désormais bien connu en matière de droit d’auteur ( La prochaine assemblée générale annuelle des actionnaires de Microsoft, qui se tiendra le 7 décembre et cette année en visioconférence (
La prochaine assemblée générale annuelle des actionnaires de Microsoft, qui se tiendra le 7 décembre et cette année en visioconférence ( L’utilisation de l’intelligence artificielle (IA) dans les domaines artistiques tend à révolutionner la manière dont nous analysons, créons et utilisons les œuvres cinématographiques, littéraires ou encore musicales. Si, dans un premier temps, on a pu y voir un moyen presque anecdotique de créer une œuvre à partir des souhaits d’un utilisateur ayant accès à une IA, elle inquiète désormais les artistes. Les algorithmes et les AI peuvent être des outils très efficaces, à condition qu’ils soient bien conçus et entraînés. Ils sont par conséquent très fortement dépendants des données qui leur sont fournies. On appelle ces données d’entraînement des « inputs », utilisées par les IA génératives pour créer des « outputs ».
L’utilisation de l’intelligence artificielle (IA) dans les domaines artistiques tend à révolutionner la manière dont nous analysons, créons et utilisons les œuvres cinématographiques, littéraires ou encore musicales. Si, dans un premier temps, on a pu y voir un moyen presque anecdotique de créer une œuvre à partir des souhaits d’un utilisateur ayant accès à une IA, elle inquiète désormais les artistes. Les algorithmes et les AI peuvent être des outils très efficaces, à condition qu’ils soient bien conçus et entraînés. Ils sont par conséquent très fortement dépendants des données qui leur sont fournies. On appelle ces données d’entraînement des « inputs », utilisées par les IA génératives pour créer des « outputs ». 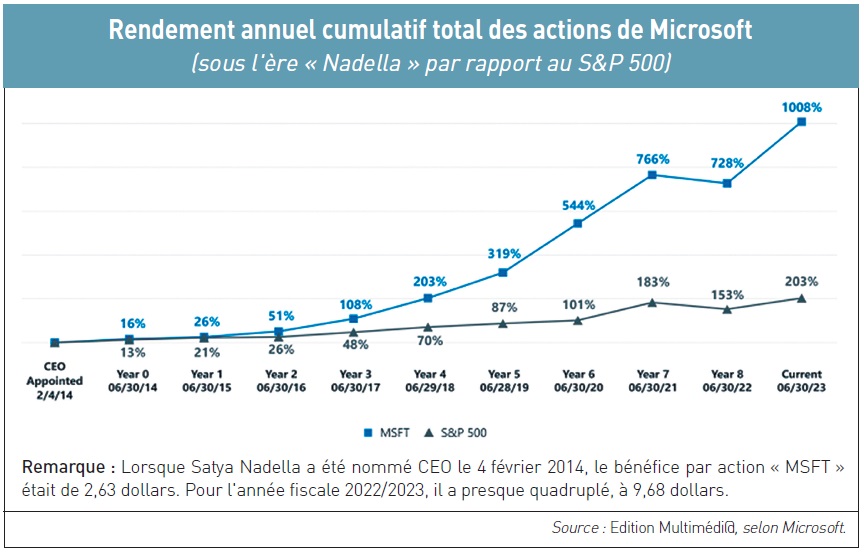{kind=link}