Claude d’Anthropic sera-t-elle l’IA générative qui pourra détrôner ChatGPT d’OpenAI ? L’avenir dira si la fable du lièvre et de la tortue s’appliquera à ces deux concurrents directs. Pour l’heure, la tortue Claude fait son chemin aux côtés d’Amazon qui va l’utiliser pour son assistant Alexa.
 Claude d’Anthropic sera-t-elle l’IA générative qui pourra détrôner ChatGPT d’OpenAI ? L’avenir dira si la fable du lièvre et de la tortue s’appliquera à ces deux concurrents Alors que ChatGPT d’OpenAI a été lancé le 30 novembre 2022 avec le succès médiatique planétaire que l’on connaît (1), son concurrent Claude d’Anthropic n’a pas dit son dernier mot depuis son lancement le 14 mars 2023 dans une relative indifférence générale (2). Mais c’était sans compter sur Amazon qui a annoncé le 25 septembre 2023 injecter 4 milliards de dollars dans la start-up cofondée par Dario Amodei (photo de gauche)et sa sœur Daniela Amodei (photo de droite), respectivement directeur général et présidente (3). Dans la course mondiale aux IA génératives, Claude fait figure de tortue par rapport au lièvre ChatGPT. Ce qui laisse un espoir pour Anthropic, la start-up qui développe le premier, de rattraper son retard par rapport à OpenAI, à l’origine du second.. Pour l’heure, la tortue Claude fait son chemin aux côtés d’Amazon qui va l’utiliser pour son assistant Alexa.
Claude d’Anthropic sera-t-elle l’IA générative qui pourra détrôner ChatGPT d’OpenAI ? L’avenir dira si la fable du lièvre et de la tortue s’appliquera à ces deux concurrents Alors que ChatGPT d’OpenAI a été lancé le 30 novembre 2022 avec le succès médiatique planétaire que l’on connaît (1), son concurrent Claude d’Anthropic n’a pas dit son dernier mot depuis son lancement le 14 mars 2023 dans une relative indifférence générale (2). Mais c’était sans compter sur Amazon qui a annoncé le 25 septembre 2023 injecter 4 milliards de dollars dans la start-up cofondée par Dario Amodei (photo de gauche)et sa sœur Daniela Amodei (photo de droite), respectivement directeur général et présidente (3). Dans la course mondiale aux IA génératives, Claude fait figure de tortue par rapport au lièvre ChatGPT. Ce qui laisse un espoir pour Anthropic, la start-up qui développe le premier, de rattraper son retard par rapport à OpenAI, à l’origine du second.. Pour l’heure, la tortue Claude fait son chemin aux côtés d’Amazon qui va l’utiliser pour son assistant Alexa.
Anthropic veut rattraper OpenAI
Mais l’issue de la fable ne s’appliquera pas forcément à la réalité. En attendant, Claude vient de franchir une étape symbolique dans son expansion en dépassant 1 million de dollars de chiffre d’affaires cumulé depuis son lancement il y a près d’un an et demi. C’est ce qu’a relevé fin août Ariel Michaeli, PDG cofondateur de la société d’analyses Appfigures, à partir des boutiques d’applications mobiles App Store et Google Play. Mais atteindre 1 million de dollars en seize semaines n’est pas un record pour autant, loin de là, puisque ChatGPT avait atteint ce mondant en trois semaines et ChatOn en onze semaines. ChatOn ? Il s’agit d’un wrapper de ChatGPT, c’est-à-dire une sorte de clone qui tente d’apporter des améliorations conviviales et de nouvelles facilités. Développé par la société AIby basée à Miami, ChatOn rencontre un certain succès aux Etats-Unis. Mais Claude a la satisfaction d’avoir atteint le million plus rapidement que Copilot de Microsoft, lequel, pourtant, a investi plus de 13 milliards de dollars dans son partenaire OpenAI (4) et a une base de plusieurs millions d’utilisateurs de son navigateur Edge intégrant Copilot. Claude a aussi franchi le million bien avant les vingt-deux semaines qu’il a fallu à Perplexity pour l’atteindre (voir graphique ci-dessous). La start-up californienne Perplexity AI, cofondée en août 2022, a lancé un moteur conversationnel intelligent (chat-search) présenté comme « une alternative aux moteurs de recherche traditionnels » (5).
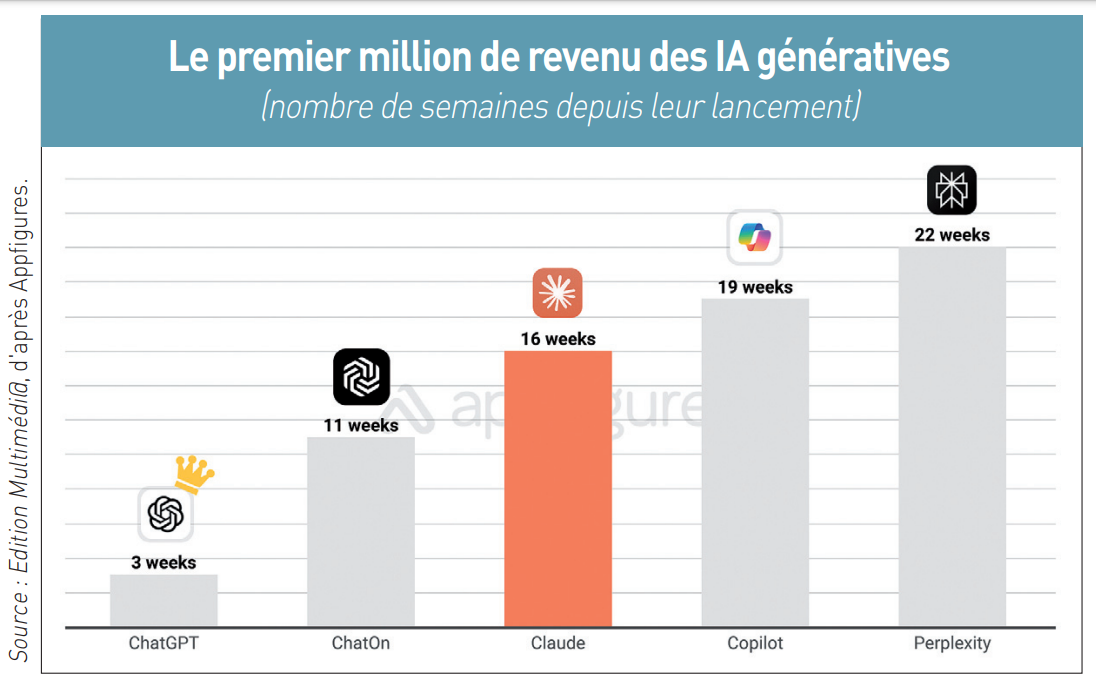 Anthropic a donc plus que jamais une carte à jouer dans la bataille des IA génératives, comme le croit Ariel Michaeli : « Nous estimons que Claude a jusqu’à présent 25.000 abonnés payants. Cela semble beaucoup, mais ChatGPT a ajouté 291.000 nouveaux abonnés payants en juillet [l’IA générative d’OpenAI revendiquant en août plus de 200 millions d’utilisateurs actifs, ndlr]. Pour que Claude ait une chance, il doit apprendre des wrappers et ne pas copier ChatGPT. Si Claude augmente son interface de chat avec des fonctionnalités plus grand public, et s’il promeut son application mobile, alors il pourrait avoir une chance » (6). La monétisation actuelle de Claude sur mobile provient à 48,4 % des Etats-Unis, 6,7 % du Japon, 4,3 % de l’Allemagne, à égalité avec le Royaume-Uni, ou encore de 2,8 % de la Corée du Sud.
Anthropic a donc plus que jamais une carte à jouer dans la bataille des IA génératives, comme le croit Ariel Michaeli : « Nous estimons que Claude a jusqu’à présent 25.000 abonnés payants. Cela semble beaucoup, mais ChatGPT a ajouté 291.000 nouveaux abonnés payants en juillet [l’IA générative d’OpenAI revendiquant en août plus de 200 millions d’utilisateurs actifs, ndlr]. Pour que Claude ait une chance, il doit apprendre des wrappers et ne pas copier ChatGPT. Si Claude augmente son interface de chat avec des fonctionnalités plus grand public, et s’il promeut son application mobile, alors il pourrait avoir une chance » (6). La monétisation actuelle de Claude sur mobile provient à 48,4 % des Etats-Unis, 6,7 % du Japon, 4,3 % de l’Allemagne, à égalité avec le Royaume-Uni, ou encore de 2,8 % de la Corée du Sud.
 La suprématie de Google (filiale d’Alphabet) sur le marché mondial des moteurs de recherche reste quasiment inchangée à fin janvier 2025 par rapport à il y a un an, et malgré la déferlante des IA génératives et autres chabots boostés à l’intelligence artificielle. D’après StatCounter, le moteur de recherche Google s’arroge encore 89,78 % de part de marché mondiale dans le search (1). L’érosion est infinitésimale comparé aux 91,47 % observés il y a un an, en janvier 2024. Les rivaux restent de petits poucets, avec Bing de Microsoft à 3,94 %, le russe Yandex à 2,74 %, Yahoo à 1,27 %, le chinois Baidu à 1,71 % et DuckDuckGo en-dessous de 1 %.
La suprématie de Google (filiale d’Alphabet) sur le marché mondial des moteurs de recherche reste quasiment inchangée à fin janvier 2025 par rapport à il y a un an, et malgré la déferlante des IA génératives et autres chabots boostés à l’intelligence artificielle. D’après StatCounter, le moteur de recherche Google s’arroge encore 89,78 % de part de marché mondiale dans le search (1). L’érosion est infinitésimale comparé aux 91,47 % observés il y a un an, en janvier 2024. Les rivaux restent de petits poucets, avec Bing de Microsoft à 3,94 %, le russe Yandex à 2,74 %, Yahoo à 1,27 %, le chinois Baidu à 1,71 % et DuckDuckGo en-dessous de 1 %. Après avoir été la première capitalisation boursière mondiale, le groupe Nvidia est redevenu la seconde à 3.314 milliards de dollars au 29 novembre 2024 (au moment où nous bouclons ce numéro de Edition Multimédi@), derrière Apple (3.551 milliards de dollars), Microsoft (3.144 milliards), Amazon (2.163 milliards) ou encore Alphabet/ Google (2.080 milliards), d’après CompaniesMarketCap (
Après avoir été la première capitalisation boursière mondiale, le groupe Nvidia est redevenu la seconde à 3.314 milliards de dollars au 29 novembre 2024 (au moment où nous bouclons ce numéro de Edition Multimédi@), derrière Apple (3.551 milliards de dollars), Microsoft (3.144 milliards), Amazon (2.163 milliards) ou encore Alphabet/ Google (2.080 milliards), d’après CompaniesMarketCap ( Quasi-monopole de puces GPU et IA
Quasi-monopole de puces GPU et IA  Elle est pour demain, ou dans dix ans. Chacun y va de ses prédictions sur l’arrivée prochaine de la « superintelligence artificielle » qui sera comparable à l’intelligence humaine. Deux ans après le lancement de l’IA générative ChatGPT par la société californienne OpenAI, mis en ligne le 30 novembre 2022 précisément (
Elle est pour demain, ou dans dix ans. Chacun y va de ses prédictions sur l’arrivée prochaine de la « superintelligence artificielle » qui sera comparable à l’intelligence humaine. Deux ans après le lancement de l’IA générative ChatGPT par la société californienne OpenAI, mis en ligne le 30 novembre 2022 précisément (